如痴如醉--为之奈何
时间:2019-11-22 浏览次数:663
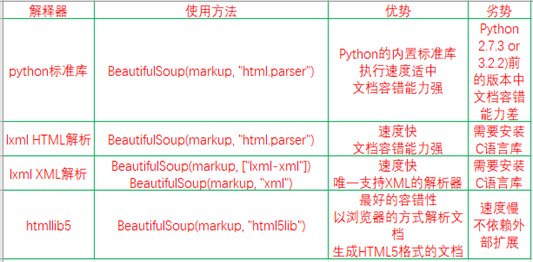
Beautiful Soup支持Python标准库中的HTML解析器,还支持一些第三方的解析器,如果我们不安装它,则 Python 会使用 Python默认的解析器,lxml 解析器更加强大,速度更快,推荐安装。
既然我们已经得到了标签的内容,那么问题来了,我们要想获取标签内部的文字怎么办呢?很简单,用 .string 即可,例如:
BeautifulSoup 对象表示的是一个文档的全部内容.大部分时候,可以把它当作 Tag 对象,是一个特殊的 Tag,我们可以分别获取它的类型,名称,以及属性来感受一下:
Comment 对象是一个特殊类型的 NavigableString 对象,其实输出的内容仍然不包括注释符号,但是如果不好好处理它,可能会对我们的文本处理造成意想不到的麻烦。
我们在写 CSS 时,标签名不加任何修饰,类名前加点,id名前加#,在这里我们也可以利用类似的方法来筛选元素,用到的方法是 soup.select(),返回类型是 list。
组合查找即和写 class 文件时,标签名与类名、id 名进行的组合原理是一样的,例如查找 p 标签中,id 等于 link1 的内容,二者需要用空格分开
查找时还可以加入属性元素,属性需要用中括号括起来,注意属性和标签属于同一节点,所以中间不能加空格,否则会无法匹配到。
上一篇:ZSW-7254支柱绝缘子 下一篇:何君尧:不畏、不悔、不退
推荐内容
- ·奇瑞、长安混改:旧包袱与新期待
- ·倾世狂妃:废材四小姐看看网友是如何评论
- ·有关各民族服饰特点具体情况是什么?
- ·关于最重要的决定范玮琪后续报道是什么?
- ·第九批在韩中国人民志愿军烈士遗骸装殓仪
- ·关于稳定的反义词是什么原因?
- ·我爱的是你爱我台词到底是怎么回事?
- ·拽少爷恋上黑道公主是什么原因?
- ·关于祭礼长生天究竟什么原因?
- ·入党党小组意见怎么解读?
- ·宝马几系是怎么区分的
- ·中共十九届五中全会在京举行
- ·最新版5元人民币来了!真颜曝光网友炸锅
- ·关于张真和英梓具体情况是什么?
- ·恋上霸道监护人究竟什么原因?
- ·关于奥运五环的含义这个事件网友怎么看?
- ·有关昨晚我捅错了洞网友怎么看?
- ·关于出(chū)乎(hū)意(yì)料(liào)为
- ·盘点男明星肌肉:蔡徐坤意想不到孙杨硬朗
- ·碧血剑江华版演员表看看网友是怎么说的!
- ·安徽埇桥再通报杂技女演员坠亡:未报备审
- ·台陆委会称9月29日起放宽陆港澳4类人士入
- ·肛(ɡānɡ)皆(jiē)袱(fú)为什么会上热
- ·终(zhōng)南(nán)捷(jié)径(jìng)背
- ·全新福特锐际:用一场千人火锅盛宴展现寒
- ·螺蛳壳里也能做大道场
- ·技术变革下P型产能即将退场
- ·地铁13号线拆分建材城东站有新进展!
- ·科士达涨1000%国信证券一个月前给出“买
- ·羊上树台词网友会有什么评论?